file文件
1 | winter@winter-ubuntu16:~/googlectf/reverse-beginner$ file a.out |
ELF二进制文件,64位,x86-64架构,LSB说明是小端的(MSB是大端的)
执行文件
1 | winter@winter-ubuntu16:~/googlectf/reverse-beginner$ ./a.out |
一个输入点,判断对错
查看字符串
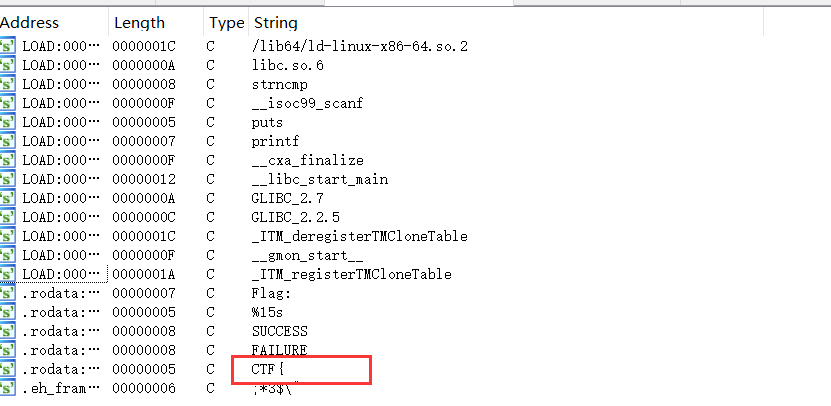
给定的字符串里面有CTF{,很可能是flag的一部分
程序流程
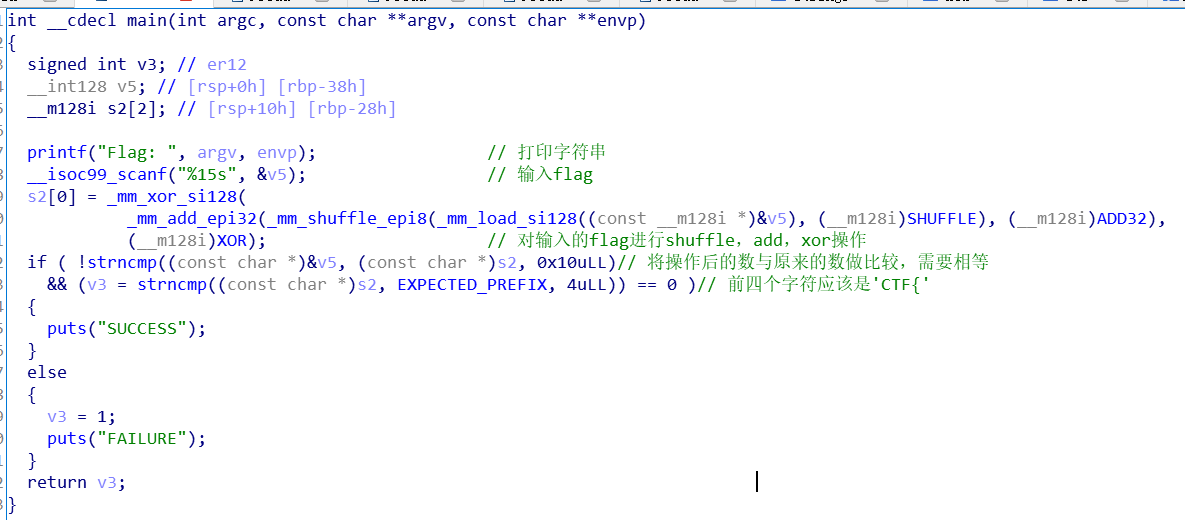
__isoc99_scanf("%15s", &v5);规定了最多输入15个字符,flag很有可能就是15个。

simd指令
全称single instruction multiple data,即单指令多数据运算
其目的就在于帮助CPU实现数据并行,提高运算效率。
shuffle
选取源寄存器的任意字节重新排布到目的寄存器。
通俗来讲:就是将原来寄存器里面字节排列,按你的要求打乱顺序,最后将打乱顺序的存入目的寄存器
网上可以搜到它的伪代码描述
1 | char a[16]; // input a |
https://www.cnblogs.com/celerychen/archive/2013/03/29/2989254.html

13 12 10 08 04 15 03 14 09 11 05 01 07 06 02
假设我们输入的值存放在a[16]数组里面
1 | 索引: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
add32
每32位(4个字节)做整形加法运算,但是进位不会从一个4字节的包传输到另一个:

xor
做异或操作

因为程序是小端的,所以实际要倒过来,可以通过右键array变过来。

拼凑flag
假设前四个字符就是CTF{,我们根据以上规则进行实验。
1 | shuffle = [2, 6, 7, 1, 5, 0xB, 9, 0xE, 3, 0xF, 4, 8, 0xA, 0xC,0xD, 0] |
根据shuffle的规则,打乱顺序后的字符串如下
1 | a[2] a[6] a[7] a[1] a[5] a[11] a[9] a[14] a[3] a[15] a[4] a[8] a[10] a[12] a[13] a[0] |
所以,一开始我们知道第三个(也就是a[3])是’{‘。
a[3]被放在了索引8的位置,我们继续计算add和xor,就可以得到a[8]了,因为操作后的要和之前的一样。
1 | 0x7B + ADD[8] = 0x7B + 0x37 = 0xB2 |
所以,就有了
3 => 8 => 11 => 5 => 4 => 10 => 12 => 13 => 14 => 7,依次类推出来所有的flag
但是,这里还有注意的是进位。
11 => 5
1 | 0x4D + ADD[5] = 0x4D + 0xDE = 0x12B |
这里发生了进位,需要将进位添加到add[6]里面去
其他的也一样。
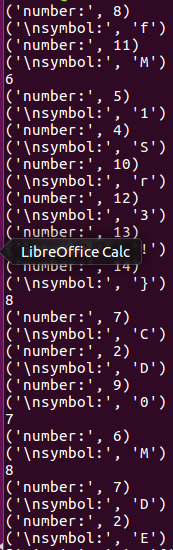
出现单个数字的,说明进位到了什么索引。
分别add[6]、add[7]、add[8]都发生了进位,但是add[6]加上进位是在第六位计算之前,所以没事。add[8]是add[7]进位,add[7]在四字节分割中是第二个四字节的末尾,所以他的进位无法添加到下一个有效字节,不用管它。
所以,最后只有add[7]在结束后都需要重新计算。
1 | a[14] + ADD[7] = 0x7D + 0xFF = 0x17C |
由于a[7]变了,相应的a[2]也会变
add[1]有进位(0x4d + 0xbe == 0x10b),add[2]=0xae
1 | a[7] + ADD[7] = 0x44 + 0xae = 0xf2 |
我们知道前面三个,这个也算是验证吧。
exp如下:
1 | import binascii |

